代价函数,或者称为损失函数(loss function)用于衡量系统输出和期望输出的误差大小,通过向着逐步减小代价函数的方向,也就是函数关于参数的梯度的负方向调整参数,我们就减小误差,从而优化模型。一般情况下我们会使用均方差(MSE:Mean Square Error)作为代价函数,因为均方差有很好的几何解释,可以视为欧几里得空间的距离。然而在神经网络中,我们会使用交叉熵(Cross-entropy)作为代价函数而不使用我们常用的均方差,原因在于神经网络中有一个特殊的部分:

设代价函数 

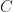


由此可以看出,下降速度除了和预测与真实值之间的差值有关以外,还乘了一个倍率。这个倍率是

交叉熵解决这个问题的方式就是构造出一个新的代价函数




又因为$sigmoid$ 函数的特殊性,我们可以用它本身来表示它的倒数,也就是

也就是我们获得了
附:简单证明

![\cfrac{d}{dx} \sigma(x) = \cfrac{d}{dx} \left[ \cfrac{1}{1 + e^{-x}} \right] \\ = \cfrac{d}{dx} \left( 1 + \mathrm{e}^{-x} \right)^{-1} \\ = -(1 + e^{-x})^{-2}(-e^{-x}) \\ = \cfrac{e^{-x}}{\left(1 + e^{-x}\right)^2} \\ = \cfrac{1}{1 + e^{-x}\ } \cdot \cfrac{e^{-x}}{1 + e^{-x}} \\ = \cfrac{1}{1 + e^{-x}\ } \cdot \cfrac{(1 + e^{-x}) - 1}{1 + e^{-x}} \\ = \cfrac{1}{1 + e^{-x}\ } \cdot \left( 1 - \cfrac{1}{1 + e^{-x}} \right) \\ = \sigma(x) \cdot (1 - \sigma(x))](https://s0.wp.com/latex.php?latex=%5Ccfrac%7Bd%7D%7Bdx%7D+%5Csigma%28x%29+%3D+%5Ccfrac%7Bd%7D%7Bdx%7D+%5Cleft%5B+%5Ccfrac%7B1%7D%7B1+%2B+e%5E%7B-x%7D%7D+%5Cright%5D+%5C%5C+%3D+%5Ccfrac%7Bd%7D%7Bdx%7D+%5Cleft%28+1+%2B+%5Cmathrm%7Be%7D%5E%7B-x%7D+%5Cright%29%5E%7B-1%7D+%5C%5C+%3D+-%281+%2B+e%5E%7B-x%7D%29%5E%7B-2%7D%28-e%5E%7B-x%7D%29+%5C%5C+%3D+%5Ccfrac%7Be%5E%7B-x%7D%7D%7B%5Cleft%281+%2B+e%5E%7B-x%7D%5Cright%29%5E2%7D+%5C%5C+%3D+%5Ccfrac%7B1%7D%7B1+%2B+e%5E%7B-x%7D%5C+%7D+%5Ccdot+%5Ccfrac%7Be%5E%7B-x%7D%7D%7B1+%2B+e%5E%7B-x%7D%7D+%5C%5C+%3D+%5Ccfrac%7B1%7D%7B1+%2B+e%5E%7B-x%7D%5C+%7D+%5Ccdot+%5Ccfrac%7B%281+%2B+e%5E%7B-x%7D%29+-+1%7D%7B1+%2B+e%5E%7B-x%7D%7D+%5C%5C+%3D+%5Ccfrac%7B1%7D%7B1+%2B+e%5E%7B-x%7D%5C+%7D+%5Ccdot+%5Cleft%28+1+-+%5Ccfrac%7B1%7D%7B1+%2B+e%5E%7B-x%7D%7D+%5Cright%29+%5C%5C+%3D+%5Csigma%28x%29+%5Ccdot+%281+-+%5Csigma%28x%29%29+&bg=FFFFFF&fg=181818&s=0&c=20201002)
