选择排序
排序思想:每次挑选最值(最大值或者最小值)然后顺序放在前面(或者后面)以达到升序(或者降序)的排序。以升序为例,从第一个开始挑选最小的放在第一位,然后再从除了第一个之后的所有元素挑选最小的,放在第二位,以此类推。
复杂度解释:显然从第一个开始挑选到最后一次挑选需要一个循环,每次挑选过程都要遍历剩下的元素,因此内嵌一个循环。算法复杂度时
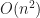
template<class T>
void select_sort(std::vector<T> &v){
for (int i = 0; i<v.size(); i++) {
int min_index = i;
for (int j = 0; j<v.size(); j++) {
if (v[min_index]<v[j]) {
std::swap(v[min_index], v[j]);
}
}
}
}
冒泡排序
排序思想:大的元素不断上升或者小的元素不断沉底。“不断”的过程可以用两个循环来实现。两两比较如果满足条件就交换。
template<class T>
void bubble_sort(std::vector<T> &v){
for (int i = 0; i<v.size(); i++) {
for (int j = i; j<v.size()-i-1; j++) {
if (v[j+1]<v[j]) { //if next one is smaller then swap
std::swap(v[j], v[j+1]);
}
}
}
}
插入排序
排序的思想:类似于扑克牌的整理,依次挑选并与之前的比较,插入到合适的位置。由于插入到之前的位置需要把该元素之前的部分元素依次后移,所以需要一个while循环来进行迭代赋值。然后最后再把要插入的元素的值覆盖到所在的位置。
注意,因为要表示下一个元素,用到i+1,所以循环要改成v.size()-1以保证不越界。同时为了避免空数组的v.size()-1<0的情况发生,还需要一个简单的if判断。
template <class T>
void insert_sort(std::vector<T> &v) {
if (v.size() > 1) {
for (int i = 0; i<v.size()-1; i++) {
T next_value = v[i+1];
int next = i+1;
while(v[next-1] > next_value ){ //if next one is smaller than previous
v[next] = v[next-1]; //overwrite the next one with privous
next--;
}
v[next] = next_value;
}
}
}
快速排序
排序思想:不断划分小块。如果在升序的情况,则划分点左边的元素值均小于划分点的值,划分点右边的值均大于划分点的值。可以先选择最后一个元素作为划分点,然后陆续遍历一次把前面所有元素和划分点比较,设置一个用来记录比划分点小的index,当遇到比划分点小的值时用来交换。遍历结束后把划分点移动到index的前面,这样就保证了左边小于划分点,右边大于划分点。一次partition的过程可以用下图说明:
template <class T>
int partition(std::vector<T> &v, int first, int last){
T pivot = v[last];
int i = first - 1;
for (int j = first; j<v.size()-1; j++) {
if (v[j]<pivot) { //如果当前值小于pivot的值
i++;
std::swap(v[i], v[j]);
}
}
std::swap(v[i+1], v[last]); //最后把pivot指的元素放在最后一个比它小的元素的前面
return (i+1);
}
template <class T>
void quick_sort(std::vector<T> &v, int first, int last) {
if (first<last) {
int pi = partition(v, first, last);
quick_sort(v, first, pi-1);
quick_sort(v, pi+1, last);
}
}
归并排序
排序思想:最后一种常用的排序是归并排序,其代码会稍长,但思路是比较容易理解的。
首先主函数每次迭代都需要计算一个新的中点,就是为了不断切分成小块,迭代地调用自身,并传入左半部分和右半部分进去。与快排不一样,快排是在分块的时候排序,而归并是在合并的时候排序,因此merge函数是在两个自身递归调用的下面。merge函数内容分为以下几个步骤:
- 创建两个
vector,分别存放左半部分[first, middle-first+1]和右半部分[middle, last-middle] - 依次把原数组的
first到middle-first+1的元素复制到左半部分 - 依次把原数组的
middle到last-middle的元素复制到右半部分 i指向左半部分第0个,j指向右半部分第0个,当i和j都不超过各自数组时,k指向原数组要被覆盖的第0个,也就是k=first。循环比较把小的重新覆盖到原数组去- 然后再用while循环把剩下的复制到原数组去
- 结束
template <class T>
void merge(std::vector<T> &v, int first, int middle, int last) {
int i, j, k;
int n1 = middle-first+1;
int n2 = last - middle;
std::vector<T> v1(n1);
std::vector<T> v2(n2);
for (i = 0; i< n1; i++)
v1[i] = v[first + i];
for (j = 0; j<n2; j++)
v2[j] = v[middle+1+j];
i = 0;
j = 0;
k = first;
while (i<n1 && j < n2) {
if (v1[i]<v2[j]){
v[k] = v1[i];
i++;
}
else {
v[k] = v2[j];
j++;
}
k++;
}
while(i<n1){
v[k] = v1[i];
i++;
k++;
}
while(j<n2){
v[k] = v2[j];
j++;
k++;
}
}
template <class T>
void merge_sort(std::vector<T> &v, int first, int last){
if (first < last) {
int middle = first + (last - first)/2;
merge_sort(v, first, middle);
merge_sort(v, middle+1, last);
merge(v,first, middle, last);
}
}
计数排序
排序思想: 通过一个计数的数组来存放各个元素应该在的位置,然后在重新拷贝到结果数组去。这里需要获得一个最大值。比如要排序[1 4 1 2 7 5 2],则需要知道最大值是7,这样才可以创建一个有7个元素的计数数组。弊端是空间的损失,如果最大值很大,则要创建的计数数组也很大。
template <class T>
void count_sort(std::vector<T> &v, int max) {
//create a count vector
std::vector<int> count(max+1);
for (int i = 0; i < v.size(); i++) {
count.at(v[i]) ++;
}
//self increment of count vector
for (int i = 1; i < count.size(); i++) {
count[i] += count[i-1];
}
//create result vector
std::vector<int> result(v.size());
//put the element in the correct position in result vector
for (int i = 0; i<v.size(); i++) {
int current_index = count[v[i]]-1;
result[current_index] = v[i];
count[v[i]] --;
}
//copy the result to the input vector
v=result;
}
堆排序
堆排序中,因为二叉堆是一个完全二叉树,因此我们可以使用数组的形式来表示二叉堆。否则就要用一些符号来填充数组某些位置以表示空节点。
数组表示的二叉堆,设双亲位置为i,i从0开始
则左孩子的位置为2*i + 1
且右孩子的位置为2*i + 2
最大堆就是双亲>左右孩子,最小堆就是双亲< 左右孩子
升序排序用最大堆,降序排序用最小堆。
def heapify(arr, n, i):
# 先把parent设为最大的,parent的位置为i
largest = i
# 然后根据公式 写出左右child 的位置 2i+1, 2i+2
l = 2 * i + 1
r = 2 * i + 2
# 如果左孩子存在,也就是l< n 且左孩子的值比largest的位置的值大
# 则设最大值的位置为左孩子的位置
if l < n and arr[largest] < arr[l]:
largest = l
# 同理判断右孩子存在与否 并和largest位置的值比较
if r < n and arr[largest] < arr[r]:
largest = r
# 如果largest的位置和parent的位置不一样,证明最大值不在parent那里
# 则将largest位置的元素和parent位置的元素交换
# 并且继续递归调用
if largest != i:
arr[i], arr[largest] = arr[largest], arr[i] # swap
heapify(arr, n, largest)
def heap_sort(arr):
n = len(arr)
# 对于数组表示的二叉堆,能作为parent的只有前 n//2 -1 个元素
# 应该从最下面的parent开始进行最大堆化,
# 这样才能保证循环完整个二叉堆都是最大堆
# 可以由不等式的方式说明
for i in range(n//2-1, -1, -1):
heapify(arr, n, i)
# 建立完二叉堆之后就是顺序取出二叉堆的元素即可得到有序数组
# 方法把第一个放到最后,然后固定最后的再把前面的最大堆化
for i in range(n-1, 0, -1):
arr[i], arr[0] = arr[0], arr[i]
heapify(arr, i, 0)
