关于SVM的笔记,因为涉及多次对偶问题以及线性规划问题的求解,故记录下公式公式推导过程,以便对SVM的基本原理有更进一步的了解。
样本点的表示
设有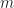

其中每个样本点为 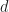

每个样本的标签取值为 

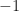
超平面的表示
设存在d维的超平面:
令
超平面方程可以写成:



(1.1)

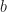
特殊地,当d=2时超平面是一条直线: 


正确分类的表示
如果一个样本

(1.4)
也就是如果超平面能正确分类样本点,则当样本点



(1.5)
样本点到超平面的距离
一个点 

(1.2)
用矩阵的形式表示W和X,同时用 



(1.3)
目标函数的确立
当样本集严格线性可分时,存在不止一种

设经过最近正样本的超平面为



(1.6)
由于最大化

因为我们要在正确分类的前提下求间隔的最大值,也就是结合式(1.5)和(1.6)转化成一个在一定约束条件下的规划问题(1.7)。

(1.7)
整合约束和目标函数
在特定约束下求最值时麻烦的,因为不能直接求目标函数最值,然后再去比较是否符合约束。最简单的方式就是引入拉格朗日算子将目标函数和约束整合在一起。设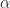
因为


(1.8)
原问题转化为一个对

(1.9)
由于先求

(1.10)
对式(1.10)的


(1.11)
(1.12)
将式(1.11)和(1.12)代回(1.10)可得到仅关于



(1.13)
根据KTT采用SMO算法解出
从线性可分到不完全线性可分
为了使某些样本可以不满足约束

(1.8)
其中
- 0/1损失函数:
- hinge损失函数:
- 指数损失函数:
- 对率损失函数:




